在大多数情况下,现代生活是十分嘈杂的。如果你不喜欢周围的喧嚣,你可以选择戴上降噪耳机,屏蔽你身边的吵闹声音。
然而,一个问题是,目前的降噪耳机会不加区分地过滤掉所有声音,其中就包括一些你真正想听到的声音。
尽管苹果的第二代 AirPods Pro 可以自动为佩戴者调整声音大小——例如,当佩戴者正在交谈时,它就会自动感应到,但他们几乎无法决定聆听谁的声音或何时聆听。
如今,一项新的人工智能(AI)技术,或将催生出一款颠覆传统的耳机——只需看一眼,整个世界都是 TA 的声音。

来自华盛顿大学的研究团队开发出了一种人工智能耳机系统——Target Speech Hearing(TSH),佩戴者只需注视目标说话者 3-5 秒钟,就可以将其“锁定”,消除环境中的所有其他声音,只选择听被“锁定”说话者的声音。即使佩戴者在嘈杂的地方走来走去,不再面对说话者时,TSH 系统也能正常运行。
“我们通常认为现在的人工智能只是基于网络的聊天机器人,被用来回答一些问题,” 该论文的通讯作者、华盛顿大学保罗-艾伦计算机科学与工程学院教授 Shyamnath Gollakota 说,“但在这个项目中,我们开发的人工智能可以根据佩戴者的喜好,改变他们的听觉感知。”
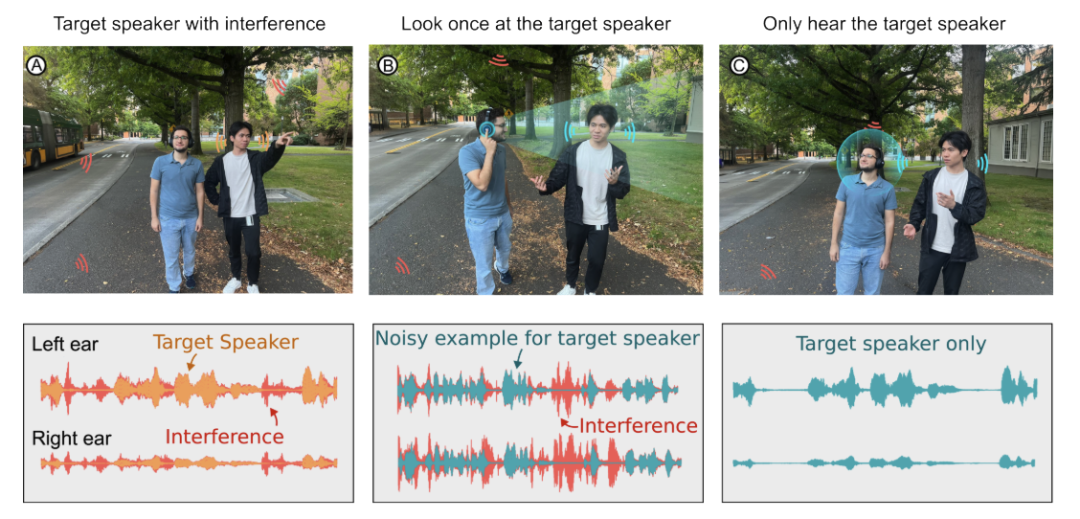
研究团队表示,TSH 系统不仅可以只听某一个人的声音,还可以只移除某一个人的声音。这在某些情况下会很有帮助,比如你想过滤掉一个人的干扰性讲话,同时还能听到其他人的讲话。
此前,研究团队已在人机交互领域最重要的国际会议—— ACM CHI Conference on Human Factors in Computing Systems 上展示了这一研究成果。
目前,这一概念验证设备的代码已可供他人使用,但尚未投入商用,他们正在商谈将其嵌入流行品牌的降噪耳机中。
此外,在未来的工作中,他们希望将 TSH 系统扩展到耳塞式耳机和助听器。
被“锁定”的声音
据论文描述,佩戴者在使用 TSH 系统时,只需要将头部对准目标说话者,然后轻按一个按钮,即可完成“锁定”。
这项工作建立在该团队之前的 semantic hearing 研究基础之上,该研究允许用户选择他们想听到的特定声音类别(如鸟叫或声音),并取消环境中的其他声音。
被“锁定”说话者的声波会同时到达耳机两侧的麦克风,耳机将信号发送到嵌入式计算机上,其中的机器学习软件开始学习被“锁定”说话者的发声模式。
TSH 系统会捕捉这些声音,并持续播放给佩戴者,即使在他们戴着耳机四处移动时。
随着被“锁定”人不断说话,系统对他们的声音的关注能力也会提高,从而为系统提供更多的训练数据。
他们在 21 名受试者身上测试了该系统,受试者对被“锁定”声音清晰度的评分平均比未经过滤的音频高出近一倍。
不足与展望
然而,这项研究也存在一些局限性。
例如,目前的 TSH 系统一次只能“锁定”一个说话者,而且只有在说话者的同一方向不存在另一个更大的声音时,才能锁定目标说话者。
在之后的工作中,研究团队希望将 TSH 系统扩展到支持同时“锁定”多个目标说话者,他们提出了两种可能的方法:
1)为每个说话者运行一个单独的网络实例,这种方法的问题是,它需要更多的计算资源,因为每个说话者都需要一个独立的处理流程。
2)训练一个能够同时处理多个说话者的网络,这个网络会使用某种形式的“聚合多说话者嵌入”,不需要为每个说话者单独运行一个实例,而是在一次处理中分离出所有说话者的语音,从而更高效地处理多个说话者。
再者,人类的语音特征可能会随着衰老、健康状况和情绪变化等因素而改变,这可能会导致 TSH 系统不能识别声音的细微差别,从而无法“锁定”目标说话者。
研究团队表示,佩戴者可以在提取目标说话者之前使用双耳可听设备捕获目标语音的注册样本,因此这一因素在短时间内可能不会有太大变化。
同时,目标说话者和干扰说话者的相似性越大,完全消除干扰说话者就越难。为了增强系统的鲁棒性,可以使用在不同时间点的多个“锁定”记录,而不只是依据一个。
另外,尽管研究团队使用了合成数据进行训练,并且能够泛化到真实世界中未见过的说话者、室内外环境以及支持移动性,但在实际应用中,模型对于不同环境和说话者的泛化能力可能还有待进一步验证和提高。
最后,他们也探讨了一些更高效“锁定”目标说话者的方法。例如,支持目标说话者的移动,这样就会降低同一方向上出现另一个强干扰说话者的概率;即使在静态场景中,训练网络只关注佩戴者所看方向上距离最近或声音最大的说话者。
参考链接:
https://dl.acm.org/doi/10.1145/3613904.3642057
https://www.washington.edu/news/2024/05/23/ai-headphones-noise-cancelling-target-speech-hearing/
在大多数情况下,现代生活是十分嘈杂的。如果你不喜欢周围的喧嚣,你可以选择戴上降噪耳机,屏蔽你身边的吵闹声音。
然而,一个问题是,目前的降噪耳机会不加区分地过滤掉所有声音,其中就包括一些你真正想听到的声音。
尽管苹果的第二代 AirPods Pro 可以自动为佩戴者调整声音大小——例如,当佩戴者正在交谈时,它就会自动感应到,但他们几乎无法决定聆听谁的声音或何时聆听。
如今,一项新的人工智能(AI)技术,或将催生出一款颠覆传统的耳机——只需看一眼,整个世界都是 TA 的声音。
来自华盛顿大学的研究团队开发出了一种人工智能耳机系统——Target Speech Hearing(TSH),佩戴者只需注视目标说话者 3-5 秒钟,就可以将其“锁定”,消除环境中的所有其他声音,只选择听被“锁定”说话者的声音。即使佩戴者在嘈杂的地方走来走去,不再面对说话者时,TSH 系统也能正常运行。
“我们通常认为现在的人工智能只是基于网络的聊天机器人,被用来回答一些问题,” 该论文的通讯作者、华盛顿大学保罗-艾伦计算机科学与工程学院教授 Shyamnath Gollakota 说,“但在这个项目中,我们开发的人工智能可以根据佩戴者的喜好,改变他们的听觉感知。”
研究团队表示,TSH 系统不仅可以只听某一个人的声音,还可以只移除某一个人的声音。这在某些情况下会很有帮助,比如你想过滤掉一个人的干扰性讲话,同时还能听到其他人的讲话。
此前,研究团队已在人机交互领域最重要的国际会议—— ACM CHI Conference on Human Factors in Computing Systems 上展示了这一研究成果。
目前,这一概念验证设备的代码已可供他人使用,但尚未投入商用,他们正在商谈将其嵌入流行品牌的降噪耳机中。
此外,在未来的工作中,他们希望将 TSH 系统扩展到耳塞式耳机和助听器。
被“锁定”的声音
据论文描述,佩戴者在使用 TSH 系统时,只需要将头部对准目标说话者,然后轻按一个按钮,即可完成“锁定”。
这项工作建立在该团队之前的 semantic hearing 研究基础之上,该研究允许用户选择他们想听到的特定声音类别(如鸟叫或声音),并取消环境中的其他声音。
被“锁定”说话者的声波会同时到达耳机两侧的麦克风,耳机将信号发送到嵌入式计算机上,其中的机器学习软件开始学习被“锁定”说话者的发声模式。
TSH 系统会捕捉这些声音,并持续播放给佩戴者,即使在他们戴着耳机四处移动时。
随着被“锁定”人不断说话,系统对他们的声音的关注能力也会提高,从而为系统提供更多的训练数据。
他们在 21 名受试者身上测试了该系统,受试者对被“锁定”声音清晰度的评分平均比未经过滤的音频高出近一倍。
不足与展望
然而,这项研究也存在一些局限性。
例如,目前的 TSH 系统一次只能“锁定”一个说话者,而且只有在说话者的同一方向不存在另一个更大的声音时,才能锁定目标说话者。
在之后的工作中,研究团队希望将 TSH 系统扩展到支持同时“锁定”多个目标说话者,他们提出了两种可能的方法:
1)为每个说话者运行一个单独的网络实例,这种方法的问题是,它需要更多的计算资源,因为每个说话者都需要一个独立的处理流程。
2)训练一个能够同时处理多个说话者的网络,这个网络会使用某种形式的“聚合多说话者嵌入”,不需要为每个说话者单独运行一个实例,而是在一次处理中分离出所有说话者的语音,从而更高效地处理多个说话者。
再者,人类的语音特征可能会随着衰老、健康状况和情绪变化等因素而改变,这可能会导致 TSH 系统不能识别声音的细微差别,从而无法“锁定”目标说话者。
研究团队表示,佩戴者可以在提取目标说话者之前使用双耳可听设备捕获目标语音的注册样本,因此这一因素在短时间内可能不会有太大变化。
同时,目标说话者和干扰说话者的相似性越大,完全消除干扰说话者就越难。为了增强系统的鲁棒性,可以使用在不同时间点的多个“锁定”记录,而不只是依据一个。
另外,尽管研究团队使用了合成数据进行训练,并且能够泛化到真实世界中未见过的说话者、室内外环境以及支持移动性,但在实际应用中,模型对于不同环境和说话者的泛化能力可能还有待进一步验证和提高。
最后,他们也探讨了一些更高效“锁定”目标说话者的方法。例如,支持目标说话者的移动,这样就会降低同一方向上出现另一个强干扰说话者的概率;即使在静态场景中,训练网络只关注佩戴者所看方向上距离最近或声音最大的说话者。
参考链接:
https://dl.acm.org/doi/10.1145/3613904.3642057
https://www.washington.edu/news/2024/05/23/ai-headphones-noise-cancelling-target-speech-hearing/

