
机器之心
科技领域创作者
2022-05-20 08:34
机器之心报道
编辑:泽南、蛋酱
对于 Mac 用户来说,这是令人激动的一天。
今年 3 月,苹果发布了其自研 ,它由 1140 亿个晶体管组成,是有史以来个人计算机中最大的数字。苹果宣称只需 1/3 的功耗,M1 Ultra 就可以实现比桌面级 GPU RTX 3090 更高的性能。

随着用户数量的增长,人们已经逐渐接受使用 M1 芯片的计算机,但作为一款 Arm 架构芯片,还有人在担心部分任务的兼容性问题。
昨天,通过与苹果 Metal 团队工程师合作,PyTorch 官方宣布已正式支持在 M1 版本的 Mac 上进行 GPU 加速的 PyTorch 机器学习模型训练。
此前,Mac 上的 PyTorch 训练仅能利用 CPU,但随着即将发布的 PyTorch v1.12 版本,开发和研究人员可以利用苹果 GPU 大幅度加快模型训练。现在,人们可以在 Mac 上相对高效地执行机器学习工作,例如在本地进行原型设计和微调。苹果芯片的 AI 训练优势
PyTorch GPU 训练加速是使用苹果 Metal Performance Shaders (MPS) 作为后端来实现的。MPS 后端扩展了 PyTorch 框架,提供了在 Mac 上设置和运行操作的脚本和功能。MPS 使用针对每个 Metal GPU 系列的独特特性进行微调的内核能力来优化计算性能。新设备将机器学习计算图和原语映射到 MPS Graph 框架和 MPS 提供的调整内核上。
每台搭载苹果自研芯片的 Mac 都有着统一的内存架构,让 GPU 可以直接访问完整的内存存储。PyTorch 官方表示,这使得 Mac 成为机器学习的绝佳平台,让用户能够在本地训练更大的网络或批大小。
这降低了与基于云算力的开发相关的成本或对额外的本地 GPU 算力需求。统一内存架构还减少了数据检索延迟,提高了端到端性能。
可以看到,与 CPU 基线相比,GPU 加速实现了成倍的训练性能提升:
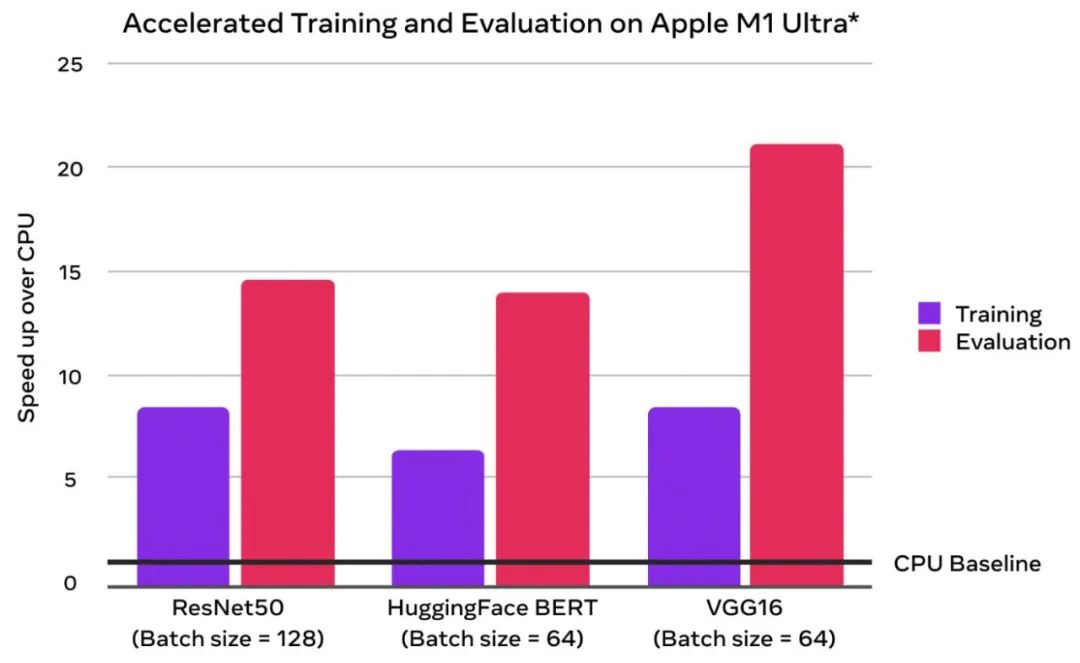
上图是苹果于 2022 年 4 月使用配备 Apple M1 Ultra(20 核 CPU、64 核 GPU)128GB 内存,2TB SSD 的 Mac Studio 系统进行测试的结果。系统为 macOS Monterey 12.3、预发布版 PyTorch 1.12,测试模型为 ResNet50(batch size = 128)、HuggingFace BERT(batch size = 64)和 VGG16(batch size = 64)。性能测试是使用特定的计算机系统进行的,反映了 Mac Studio 的大致性能。
有开发者推测,鉴于谷歌云服务中使用的英伟达 T4 在 FP32 任务上的浮点性能为 8 TFLOPS,而 M1 Ultra 的图形计算能力大概在 20 TFLOPS 左右。在最有利情况下,可以期望的 M1 Ultra 速度提升或可达到 2.5 倍。若想使用最新的加速能力,你需要在使用 M1 系列芯片的 Mac 电脑上安装原生版本(arm64)的 Python,并将系统升级至 macOS 12.3 预览版或更新的版本。
开发者亲测:加速效果显著
虽然官方已宣布提供支持,但目前还不是所有在 PyTorch 上的模型都能用 M1 芯片集成的 GPU 加速,你也可以花几分钟进行一下测试。
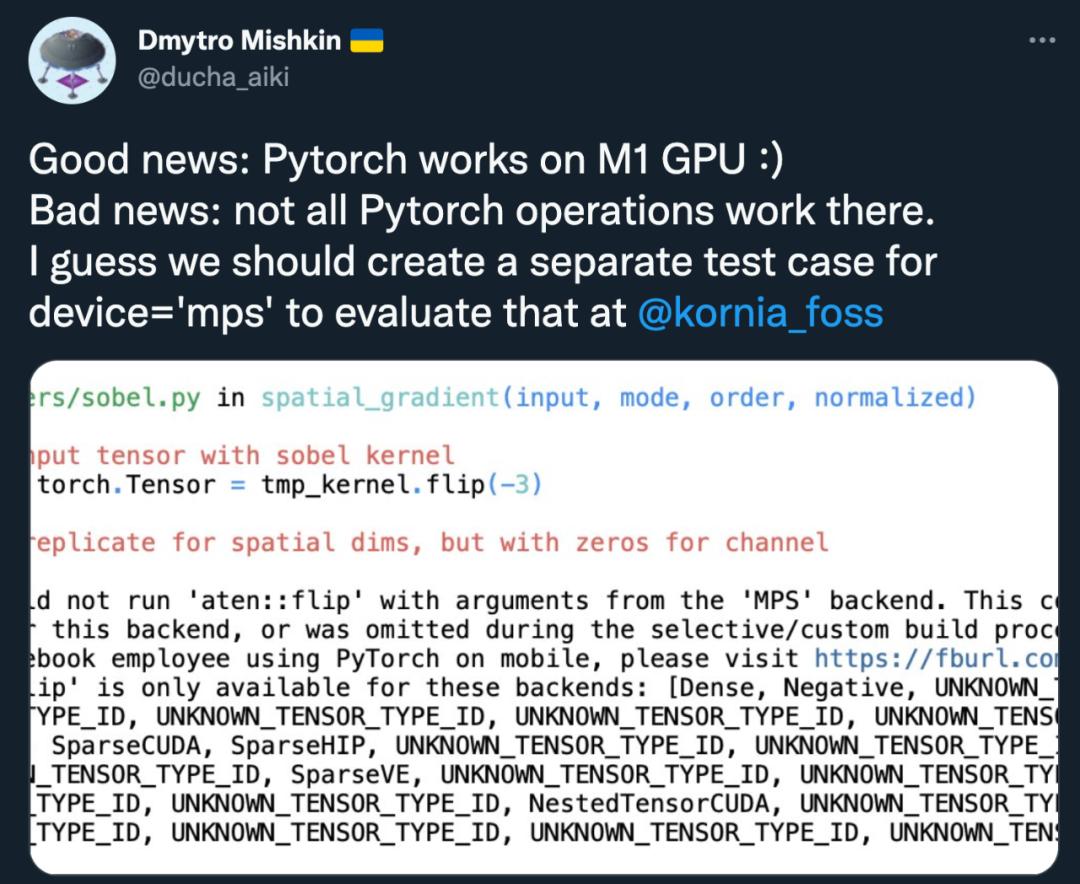
机器学习研究者,捷克理工大学博士 Dmytro Mishkin 对多个模型的推理进行了测试,结果显示,大多数图像分类架构都提供了很好的加速。对于一些自定义代码(比如 kornia),可能无法正常工作。
各个测试结果如下:
首先是经典的卷积神经网络 VGG16,从 2.23 秒提升到 0.5 秒:接下来是大部分芯片发布会上都会跑的 Resnet50,它在 M1 GPU 上的速度较慢,不升反降,从 0.549 秒到 0.592 秒:但 ResNet18 的提速惊人,从 0.243 秒到 0.024 秒:AlexNet 的速度对比为 0.126 秒 vs0.005 秒,速度提升了几十倍:尝试一下视觉 transformer 模型,在 M1 CPU 上的速度是 1.855 秒,在 M1 GPU 上则运行崩溃了……EfficientNetB0 实现了 2.5 倍的加速:EfficientNetB4 实现了 3.5 倍加速:ConvMixer 运行良好,从 11 秒提速到 2.8 秒:

Dmytro Mishkin 也表示,使用 M1 芯片集成的 GPU 加速只需要预热一下模型,没有同步命令。和 CUDA 不同,无需异步执行。威斯康星大学麦迪逊分校助理教授 Sebastian Raschka 也对 M1 芯片的 GPU 机器学习能力进行了一番测试,他使用的芯片是 M1 和 M1 Pro。
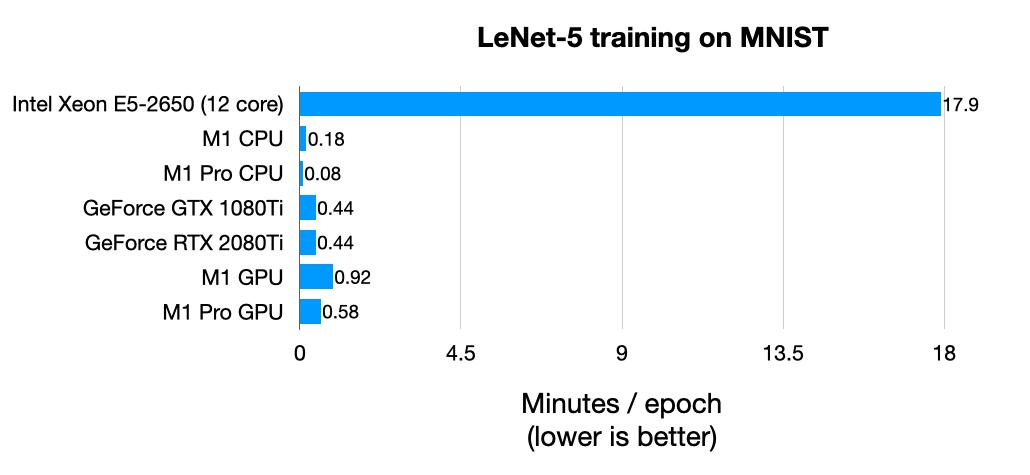
看上去,M1 CPU 似乎比 M1 GPU 更快。但 LeNet-5 是一个非常小的网络,而 MNIST 是一个非常小的数据集。如果用 rescaled CIFAR-10 图像再试一次,结果如下:
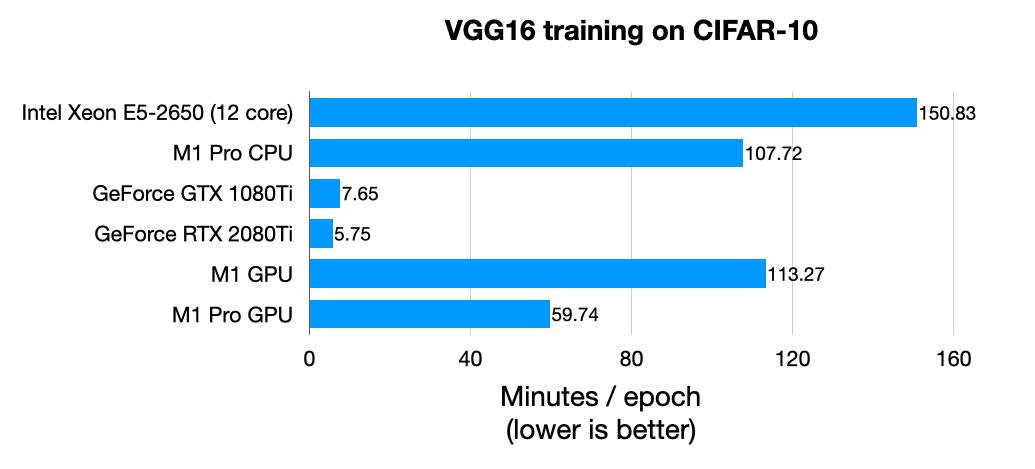
与 M1 Pro CPU(正数第二行)和 M1 Pro GPU(倒数第二行)相比,M1 Pro GPU 训练网络的速度提高了一倍。
可见,M1 系列芯片的 GPU 加速结果非常可观,在部分情况下已能满足开发者的需求。不过我们知道在 M1 Ultra 这样的芯片中也有 32 核的神经网络引擎,目前却只有苹果自己的 Core ML 框架支持使用该部分获得加速。
不知启用了 Neural Engine 之后,M1 芯片的 AI 推理速度还能提升多少?
参考内容:
https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/
https://sebastianraschka.com/blog/2022/pytorch-m1-gpu.html
5 月 21 日,机器之心组织的「ACL 2022 线上论文分享会」将在机器之心机动组视频号直播,整体日程如下,欢迎大家扫码关注。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
特别声明
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。
打开APP,阅读体验更佳

